
SUGILITE
(CMU Human-Computer Interaction Institute REU Internship)
Completed: Summer 2020
SUGILITE: the name of a pink-purple rock, and a character on the Cartoon Network animated show, Steven Universe.


But, since I was a Research Intern at Carnegie Mellon’s Human-Computer Interaction Institute (HCII), SUGILITE refers to a multi-modal smartphone intelligent Android agent that allows users to use programming by demonstration (PBD) & natural language instructions to teach it to perform various tasks in different third-party apps.
I worked under my Ph.D. mentor Toby Li as well as Professor Brad Myers, and this opportunity was via CMU’s REU program (Research Experiences for Undergraduates) in their HCI Institute (check it out here). I wanted to reflect upon my experiences and what I learned. To skip technical mumbo-jumbo, feel free to glaze over the recaps. Otherwise, let’s get started!
Brief Table of Contents
prep, problems, goals
project 1/2: fuzzierLookup (recap, challenges, iterations)
project 2/2: time expressions (recap, challenges, iterations)
key takeaways
1. prep, problems, goals
For SUGILITE, the core problem I had to address was the app’s semantic parsing: translating a user utterance into a logical, executable form that can automatically execute a script, such as ordering some kind of drink via the Starbucks app (e.g. “order a coffee” → call (get “order something”) procedureName call set_param (string “drink name”) (string “coffee”)).
(For a bit of context, SUGILITE’s main purpose is to address the domain limitations of intelligent agents like Siri or Alexa - it uses various app interfaces to learn how to automate smartphone tasks across apps and different domains. For instance, knowing how to use the Weather and Starbucks app to retrieve information to execute a simple command, “order an iced latte if it’s hot”).
Oh, and in my kind of freaked-out fashion, I decided to do some semantic parsing prep in the few weeks leading up to the internship. I:
Realized the idea of lambda calculus from learning OCaml in CS51 won’t be leaving me anytime soon
Read and outlined my mentor’s thesis proposal paper
Did Codecademy Java brushup (it’s been a while since taking AP CS in senior year!)
Got annoyed with myself for not taking Semantics in the spring, before reminding myself I got to do a cool R/Python twitter analysis instead
Read and outlined a good chunk of a Semantics textbook
Set up Linux on my Windows machine via WSL & VSCode (quite a nightmare. Let this be a cautionary tale - please just get an Apple computer)
Set up SEMPRE and briefly did the tutorial
Read papers and/or watched video tutorials, took notes on:
Because of my interest in natural language processing, and also because I was a complete newbie to any kind of research or internship for that matter, I decided to set some modest, overarching goals as well:
Have an independent contribution that I implement
Build a new skill (become more expert in NLP)
Understand how my work fits into the overall project goals
2. project 1/2: fuzzierLookup
[ recap ]
Key Tools: Java, SEMPRE framework (Stanford CoreNLP), WordNet
After onboarding, getting familiar with the codebase, and overcoming some challenges (see below), I set out on the central part of my summer experience: fuzzierLookup.
Zooming into the semantic parsing problem, I worked on how to match a user instruction to commands the agent has stored, with increased flexibility. For instance, my agent knows the utterance “call a taxi” and I say “get me a cab,” how could SUGILITE know to match those two up?
Before, the “fuzzy lookup” method just checked whether a searched utterance versus a stored utterance contains the first or last word of the other (so, “call a taxi” would not match to “get me a cab”).
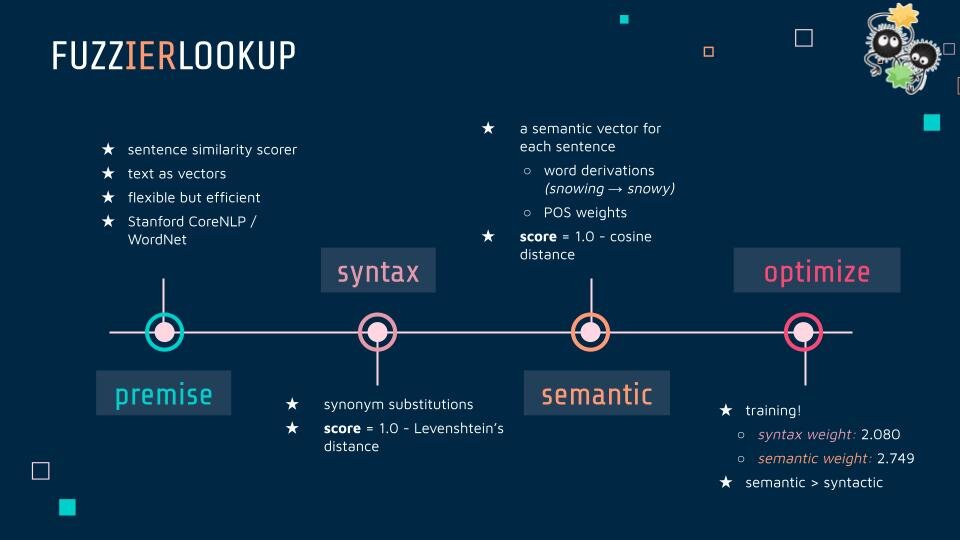
So, I designed a fuzzierLookup: a sentence similarity scorer between the lexicon utterance and the user utterance to retrieve possible answers, inspired by concepts/papers I read about NLP, information retrieval, corpus/sentence/string similarity-scoring techniques, and even some measures of machine translation accuracy (ex: BLEU). I leveraged Stanford CoreNLP and was incorporated WordNet, a lexical database. A key principle in my design choices was that the end goal was to retrieve stored procedures for an end-user, rather than a most accurate similarity scorer. For instance, I adjusted to less computationally intensive methods and reconfigured to store local caches of data to account for speed/efficiency. Moreover, buy a coffee/buy a tea, and I am at Starbucks/I am near Starbucks are very similar semantically – but are very distinct in regards to user tasks, which is why my scorer was purposely stricter in the word-relation aspect.
First, to calculate a syntax (sentence structure) score, I substitute in any word roots/synonyms into the two sentences, then find a score of 1.0 minus the normalized Levenshtein’s distance, which calculates order variability.
I calculated the semantic similarity by 1.0 - the cosine distance between two vectors of size n, for n unique words amongst the two sentences. Each vector represents the semantics of each sentence with component scores determined by the presence of the word/synonym/root, weighed by its part-of-speech and frequency to prioritize content words (e.g. verbs, nouns) and rarer words.
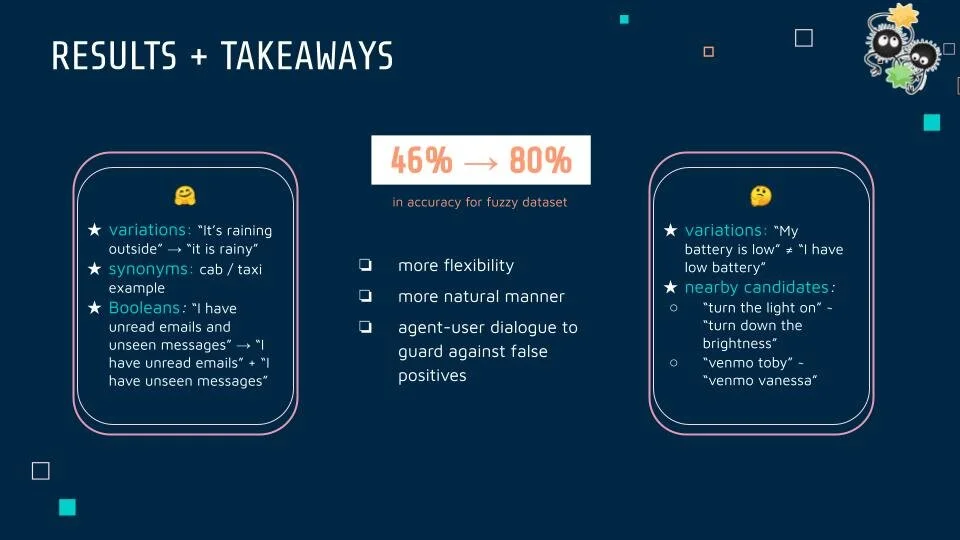
Finally, I optimized the weight given to these two scores when retrieving possible sentences by training the data. This resulted in a 46% to 80% improvement in accuracy for the dataset we used for testing, being able to handle synonyms (like taxi/cab), increased variation, such as “it’s raining outside” to “it is rainy”, and it could link Boolean operators with more flexibility, knowing that “I have unread emails and unseen messages” is equal to “I have unread emails” AND “I have unseen messages”.
There are still restrictions in variation: not recognizing My battery is low” is “I have low battery,” and interesting “nearby” candidates, with “turn the light on” close to “turn down the brightness.” The iterative dialogue between the agent and user to confirm choices thus remains an important safeguard against incorrect retrievals, which is still less costly than over-generous procedure retrievals that are harder to reverse.
So, with a fuzzier lookup functionality than before, SUGILITE users can give commands to execute with more flexibility in their speech, and thus interact with the agent in a more natural manner!
[ challenges ]
Getting all the code-base, debugger and parser set-up on VSCode (after an emotional roller-coaster of 2 days. Thank you to my mentor for his everlasting patience with Windows.)
Familiarizing myself with parser rules and the workflow of the codebase: I ended up needing to diagram it out in an actual notebook.
Figuring out how to incorporate the surprisal measure (hint: found a csv file of word frequencies online, and read it into a local cache)
Navigating WordNet (also, handy Googling)
Running many training instances to debug 100000 typos in my datasets, also general debugging for everything! Learning how to use a debugger efficiently was a difficult but rewarding experience. The pain of seeing literally thousands of NullPointerExceptions is… quite painful.
Scaling my idea to an appropriate efficiency (see iterations!)
Finding purpose in my work (see key takeaways)
[ iterations ]
After building my initial similarity scorer, I had to make many more adjustments, after retraining the model and such, to improve my results in either efficiency (not taking 10000 years to generate a score), or accuracy. So, a couple included:
Scaled up syntax score by replacing lemmas and synonyms in the sentences
Reconfigured queries with a new class to avoid repeated WordNet retrievals
Use simple heuristics to avoid noisy data (ex: any score < 0.4 → 0) and eliminate unlikely matches (if sentences differed in word count by 3+ words)
To avoid repeated computations, set up local caches to store already-computed scores for phrase pairs
At the end of the program: with the initial class hierarchy I set up, I decided to take the risk and refactor my scorer with separate classes for cleanliness, which made training 3x as fast. I was so angry at myself, and pleased at the time time.
Completely refactored fuzzierLookup to generate two separate scores and weigh them separately in training for maximized accuracy
incorporated POS weighing into the semantic score for increased accuracy
Below are the slides I used to present my fuzzierLookup at the end of the internship! The 5-minute time constraint unfortunately didn’t allow me to mention part 2.



3. project 2/2: time expressions
[ recap ]
Key Tools: Java, SEMPRE framework (Stanford CoreNLP), SUTime
Whereas fuzzierLookup focused on improvement of an existing feature, I brainstormed the time expressions feature to expand the semantic parsing rules: to include three time-related functionalities so the user can indicate the timing of when they want commands to be executed: execute_time, when the user lists a specific time they want; delay_by, an amount of time after which they want to perform the command; and set_habit, for a regularly recurring command to be executed.
I leverage the SUTime annotation pipeline included in Stanford CoreNLP to recognize and parse time expressions in user utterances. Additional time-handling functions I wrote are kept in a class called MyTimeUtils. (for the examples, the reference time of times was Thursday, July 16, 2020 at 2 pm.)
execute_time: MyDateTimeParseFn parses time phrases into a datetime value. It ignores unclear times to today (so it executes now), and delays accordingly if a time uttered is before this day (ex: Tuesday at 3 pm is for next week). It calls execute_time on the datetime with MyExecuteTimeFn.
Examples: 9 am tomorrow, at 8 pm, at 5 pm today, tonight at 9 pm, tomorrow, on August third at 5 pm, on Monday, At 12 pm next Saturday, on April 1 at 10 am
delay_by: MyTimePeriodParseFn parses durations, and MyDelayTimeFn calls delay_by on the number of milliseconds of the delay.
In an hour, in 10 minutes, after thirty minutes, after 3 hours
set_habit: MyTimeSetParseFn parses temporal set phrases (corresponding to a recurring set of times such as every Monday; in this set-up, I represent this by the next closest occurrence, and the period of time that it needs to be delayed between each occurrence). MyTimeUtils methods I wrote calculate the next closest occurrence of a temporal set and extracts the repeated amount of time between occurrences. Through betterIntersect in MyTimeUtils, it also helps resolve expressions unrecognized as sets (ex: combining every day + 3 pm, or Thursdays + 8 pm).
every day at 1 pm (starts tomorrow), 3 pm on Thursdays, 9 pm every day (starts from today), every March 18 (starts next year) 11 am Thursdays, every Monday at 9 am
[ challenges ]
Working with the SUTime API and annotation pipeline: From temporal sets to durations, I had to spend a lot of time getting familiar with how SUTime categorized different types of time expressions.
Scaling up time types and functions: While SUTime had some functionalities, I had to create a separate class (MyTimeUtils) to do my own parsing or time resolution methods, such as finding the next closest occurrence of a repeating set of times (ex: every day at 3 pm). I also had to scale up the object types to include various time types.
Incorporating common-sense time ideas
When the time isn’t specified (ex: do tomorrow), the current time is filled in as the time.
SUTime would give Tuesday, if today’s Friday, as the already-passed Tuesday - so I’d have to manually resolve that to the following Tuesday.
[ iterations ]
Reconfigured so delay_by and set_habit used milliseconds in their parameters, which is easier to take and execute on the client-side.
Time expressions are more often parameters: ex, choosing from a list of reservation times for a command “make a reservation”, but my dataset examples failed to pass training for those examples. So, I added a feature to give preference to choosing time expressions as parameters, over an execution time.
Other Features
This technically improves all the parsing and took up its own mini-part (~1 week) but I kept a huge data tracker and tested features incrementally, used in the log-linear (max likelihood) model, to see which helped improve accuracy. Some helpful ones included time parameter (above), dependency parsing; unhelpful ones included surprisal (more useful as incorporated into similarity scoring), polarity.
4. key takeaways
a. set clear but flexible goals
Like I mentioned in the Challenges for fuzzierLookup, I struggled the first few weeks to find realistic but tangible goals, and thus a sense of purpose in my work. I felt overwhelmed by not knowing what I'm doing: imposter syndrome (But later on, I realized that this was part-and-parcel of the onboarding experience)!
So, I decided to meet with our program's research advisor for advice. That helped me work with my mentor to brainstorm concrete deliverables, and plan realistic but tangible goals while staying flexible. I ended up creating a list of key goals, as well as goals for weekly predicted outcomes, which I would visit at the beginning of each new week to realign based on whatever happened prior.
So, after this encouragement, I chose the workable, interesting goal to work on: calculating sentence similarity for the FuzzySimpleLexicon functionality of SUGILITE! The rest is history.
b. have measurable results
This is CRUCIAL for any kind of work: a way to measure and/or reflect on all the progress you have made. For me, I kept daily activity logs with helpful resources I used, weekly reflections (which are helping me write this!), and the weekly goal document I mentioned above. Whenever I felt discouraged, I scrolled down this huge log and remembered all the work that I accomplished.
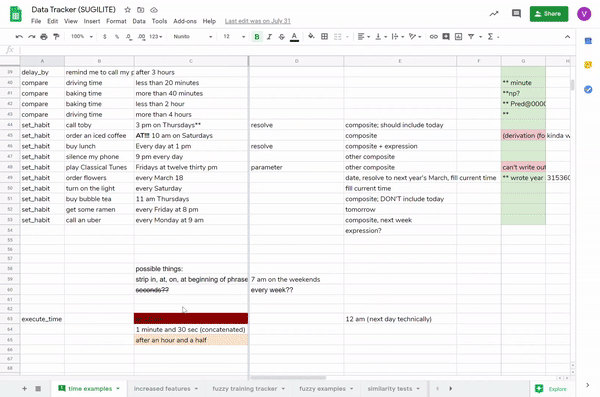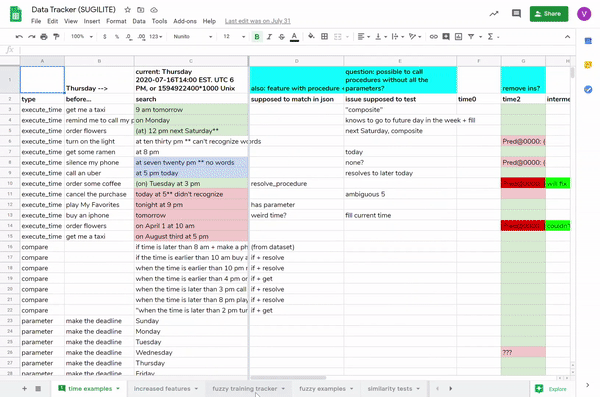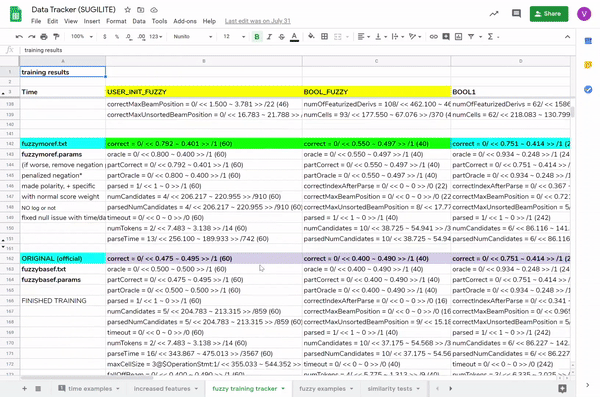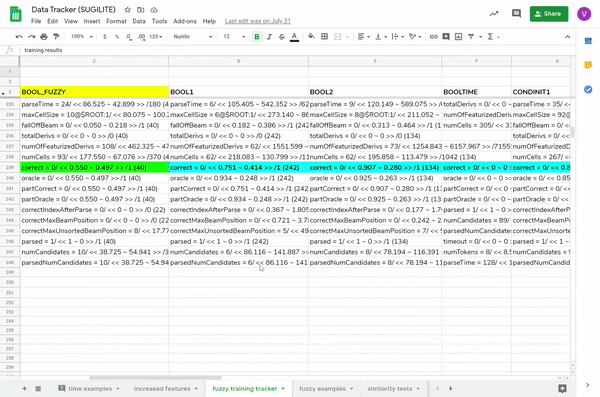
More literally, because training all those datasets would generate parsing results and scores, I kept some hefty spreadsheets to track before/after scores for datasets, specific example results to know what did/didn’t work, accuracies, time spent parsing (which was agonizingly slow in the beginning) (final result: 46% → 80% for fuzzierLookup!).
c. leverage honest (two-way) communication!!!
Especially for a remote internship and for one where I was the only intern on my portion of the project, I soon realized how crucial communication was and set up brief, daily meetings with my mentor to keep me grounded and ask for clarification. Moreover, when I was unsure of my direction or felt like I was losing steam, I steeled myself to talk it out: and was able to gain much-needed pointers. Outside of work, I asked my sister for advice on how to advocate for myself in this research experience, and an upperclassman friend even connected me with a student who did the HCI program last summer, where I talked through my thoughts with them.
In addition to voicing your thoughts, taking in feedback from others is just as important. For instance, my professor gave me an unexpected amount of feedback on my brief presentation practice -- but after considering how to incorporate those pointers, I was able to adjust my explanations and slides to much more effectively communicate my development process. And outside of work talk, just chatting with fellow researchers and mentors about pre-COVID travels or coding languages or anything, is so important to forming trust and friendly bonds! Even if there are inevitable awkward pauses, thanks to Zoom :)
c. be confident (but not comfy)
An off-shoot of the advice I received: I realized that a bit of fear and pressure to succeed can inspire me to action, but not if I'm paralyzed by failing to meet expectations that are either a) set by others who don't know me, or b) set by me, for an unrealistic ideal to achieve. So, I learned to better trust my own skills and be confident in my ability to learn: whatever I do that allows me to learn just a bit more everyday, is a success. ( brief departure, but I think I like Java better than Python. Fight me).
I also learned that if everything works, I’m not taking enough risks: and that really struck me. One of my weaker points is wanting to structure everything: goal-setting and the like, but that leads me to avoid riskier, unplanned-for paths. I could have taken more risks in my research, so I hope I take this with me to my other endeavors, and trust my resilience to help me navigate rockier waters in the future.
d. you never know what you’ll find…
*cheesy quote about how it’s about the journey, not the destination* A list of cool things I did/discovered, not directly related to my actual work:
Helped organize and participate in #ShutDownSTEM with other REU students to educate myself and learn about #BlackLivesMatter
Met fellow student researchers through cute social events, like Skribbl.io, coffee chats or online scavenger hunts!
Attended the ACL2020 Conference under CMU funding, and learned a lot about NLP and the cool academic community in linguistics/CS!
Realized how expansive and cool human-computer interaction really is after learning about exciting research happening in the field right now: from coding, data, design to psychology and more.
TLDR: this REU experience challenged me to tackle intimidating, independent projects, problem-solve iteratively, learn new skills on-the-spot, navigate unfamiliar frameworks, and take ownership of my work. I increased my resilience, and the confidence in the genuine heart and effort I put into anything I resolve to do. Because of this internship, I have a much clearer idea of what I want to explore, academic- and career-wise, in the upcoming years. I wish I was in Pittsburgh to enjoy the REU rather than my bedroom (all the cute cafes I could’ve gone to! I could’ve even visited Duolingo headquarters, for goodness sake!), but I’m keeping this metaphorically-whirlwind of a summer - my first research experience, my first internship, my first global pandemic, the usual - in my back pocket as something special.