
Analyzing Sentiment in COVID-19 and China-Related Tweets
Completed: May 2020
(A precursor): This spring semester, I kind of jumped off my expected course-path and decided to take LING190, or Harvard’s Quantitative Methods in Linguistics class. I was the only the first-year, with a smattering of sophomores, some more upperclassmen, and a healthy number of graduate students.
I was debating between taking this course and a fundamental Semantics class. And, I would’ve LOVED to take Semantics, but after realizing large lecture-style learning wasn’t my strongest suit, even for subjects I enjoyed, I wanted to try a smaller, seminar lecture-style class — as well as challenge myself outside the first-year community bubble that Harvard cultivates.
A lot of LING190 was trial-and-error, and it was much more of a self-driven process when I needed assistance, from learning R for the first time via StackOverflow, to chatting with my professors and TF over Zoom and email. Now, I am proud to have put all my cumulative efforts towards my finished final research project: Analyzing Sentiment in COVID-19 and China-Related Tweets!!
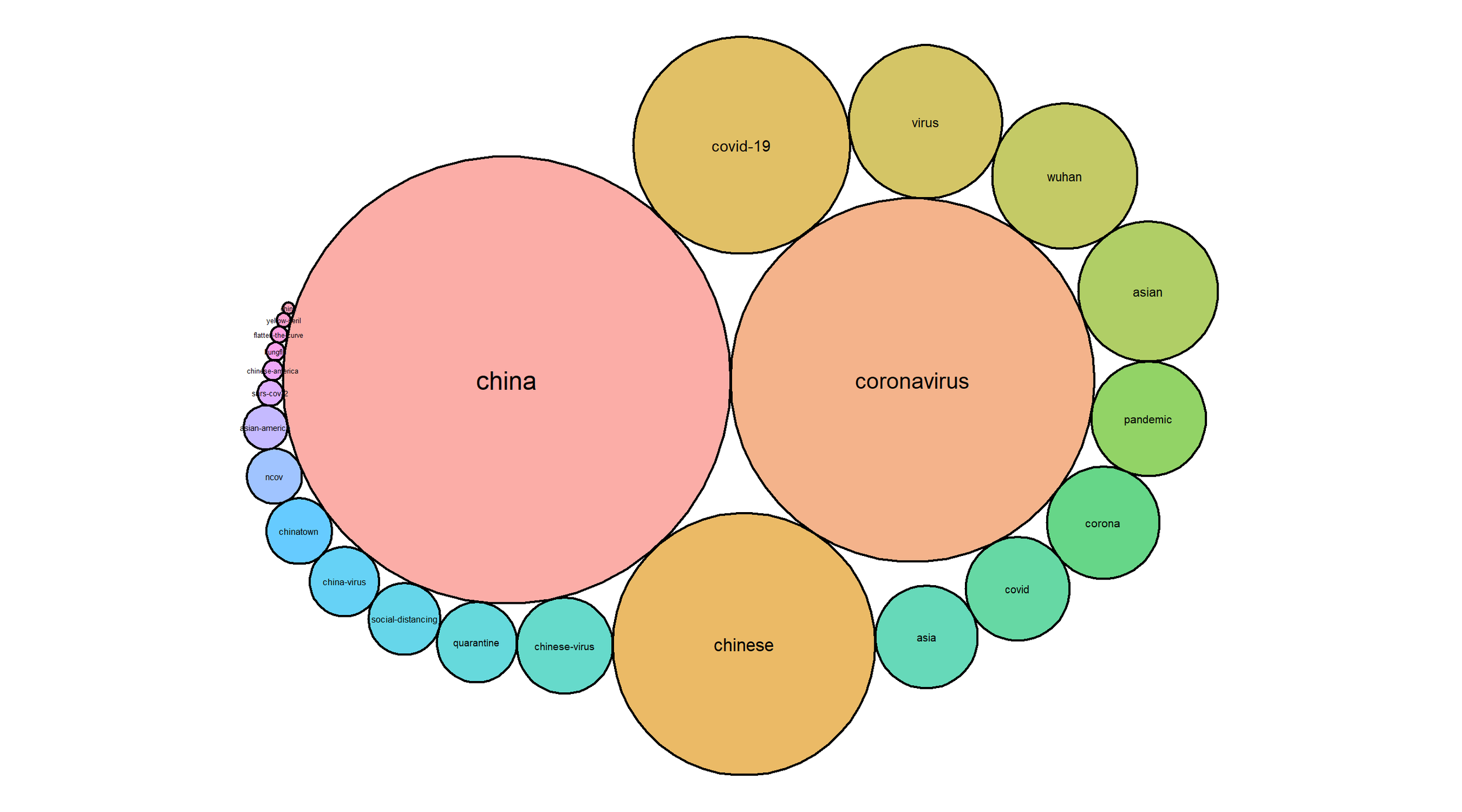
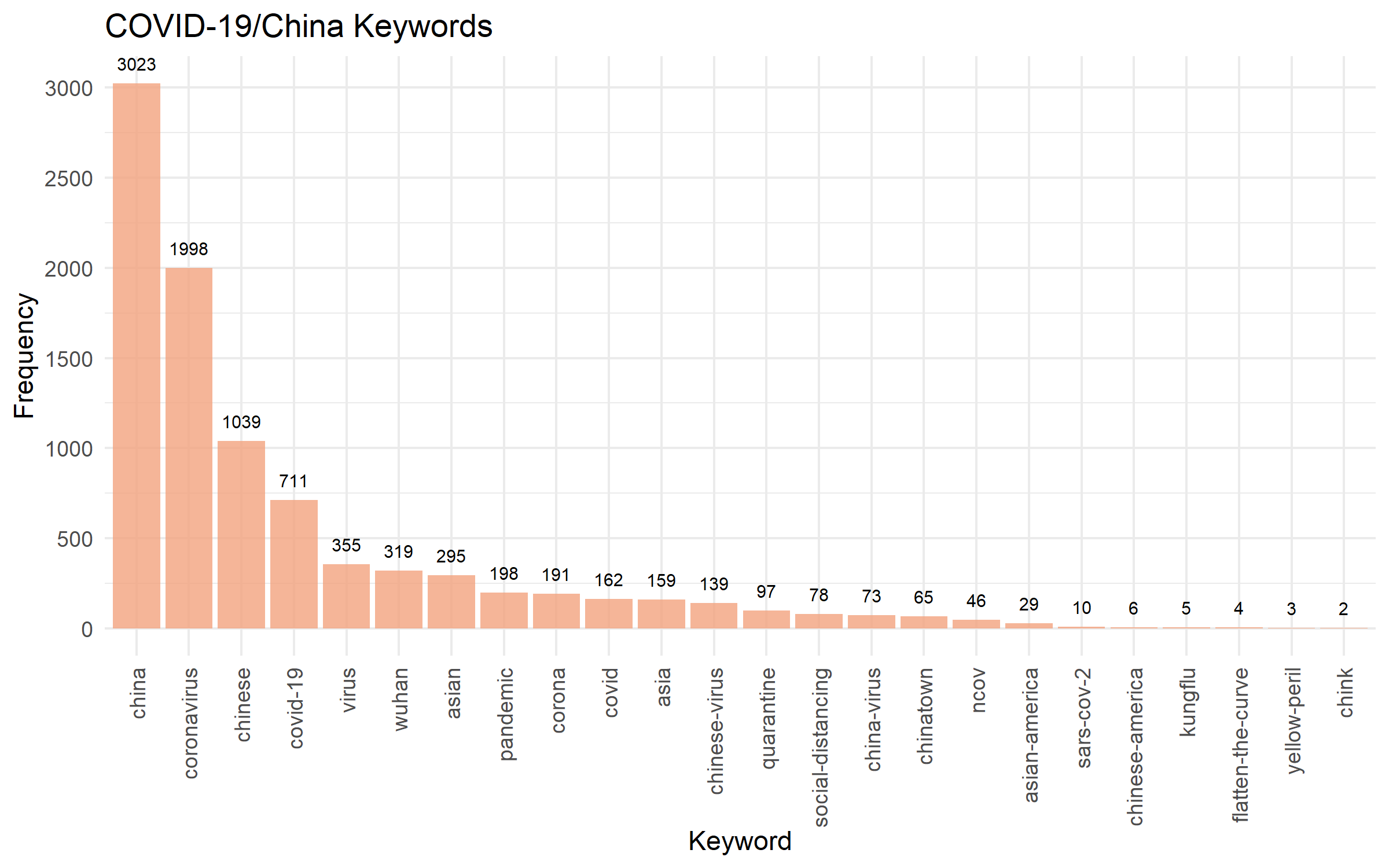
Representations of the keywords the COVID-19 and/or China tweets were tagged with.
For a taste of what I investigated, here is an edited introduction to my paper:
paper abstract & intro
The 2019 novel coronavirus outbreak (COVID-19), declared by the World Health Organization to be a pandemic in early March of 2020, has drastically impacted economies and societies across the world. From governments locking down city, state and national borders, non-essential businesses shutting down, to citizens self-isolating for the foreseeable future, our daily lives have transformed as we face this unprecedented global crisis.
An unfortunate consequence of the resulting fears and anger surrounding COVID-19, which was first identified in Wuhan, China, is rising anti-Chinese rhetoric, linking the blame for the pandemic to ethnic and national identity [1]. This has resulted in the spread of derogatory and misleading terms via social media such as “kungflu” or “Chinese virus” and “over 1700 incident reports of verbal harassment, shunning, and physical assaults” against Asian-Americans in the United States as the wider Asian population become subject to resentment and discrimination [2, 3]. Moreover in its COVID-19 and The Need for Action on Mental Health, the United Nations has emphasized the increased risk for anxiety, depression, and other mental health issues exacerbated by the pandemic [4].
Aggregating a dataset of tweets both related and unrelated to COVID-19 and China from February 2020 to April 2020, this paper investigates the sentiments of the Twitter community in the context of the global coronavirus pandemic. The findings indicate a link to more negative sentiment surrounding online dialogue regarding COVID-19 and China-related topics, as well as possible links to how sentiment towards COVID-19 or China may have respectively increased and decreased in positive sentiment over the three-months. Because with social distancing, people are turning to digital communities more than ever to participate in global dialogue and express uncertainties, fears and anger, this paper aims to investigate the sentiment of Tweets having to do with COVID-19, as well as China and Asian-Americans, to better understand the attitudes of online communities in this global crisis.
If you’d like to look at the paper or code more in depth, it’s all on my Github repository below :)
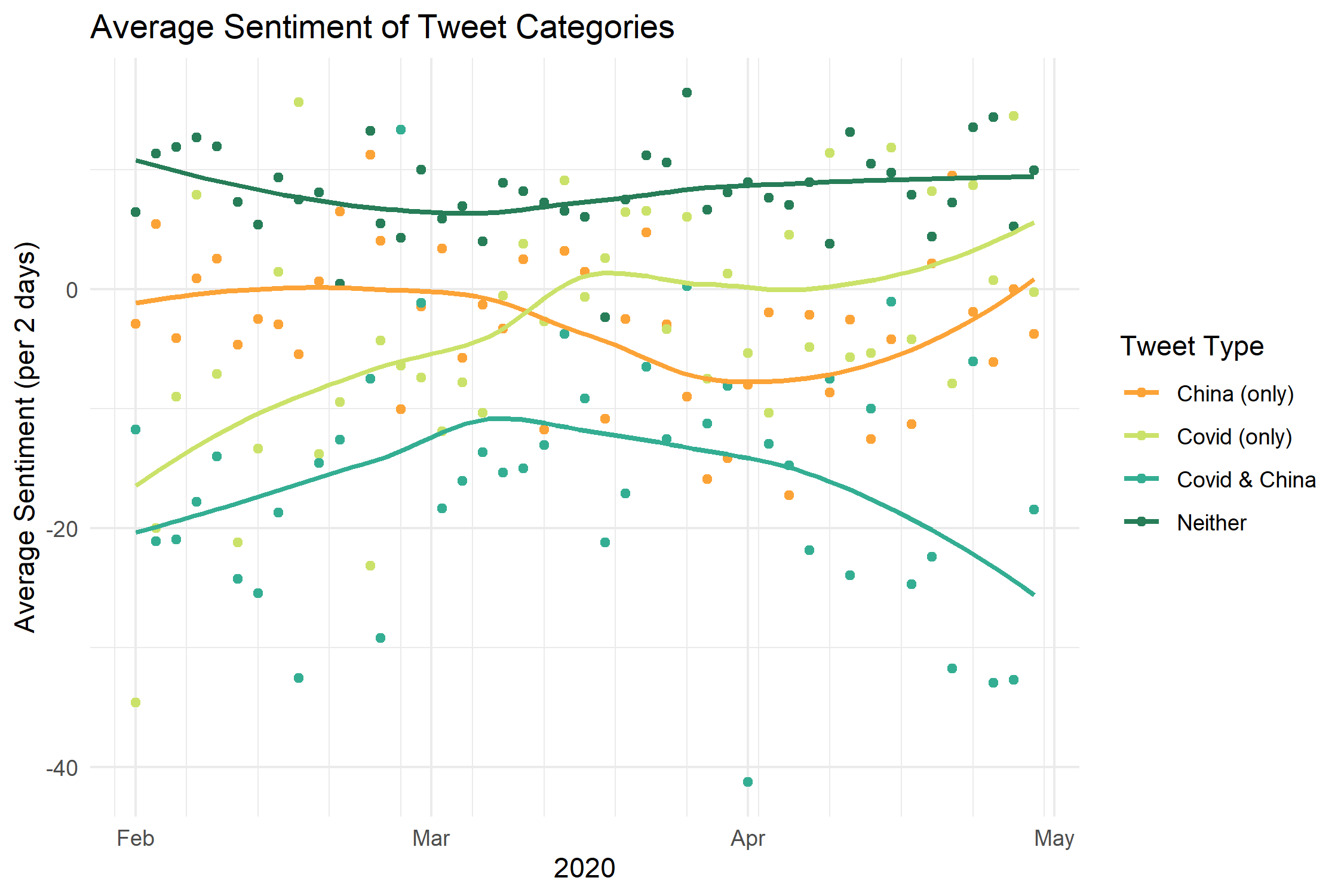
some more graphs
Check out the paper for more context and significance info on the data!
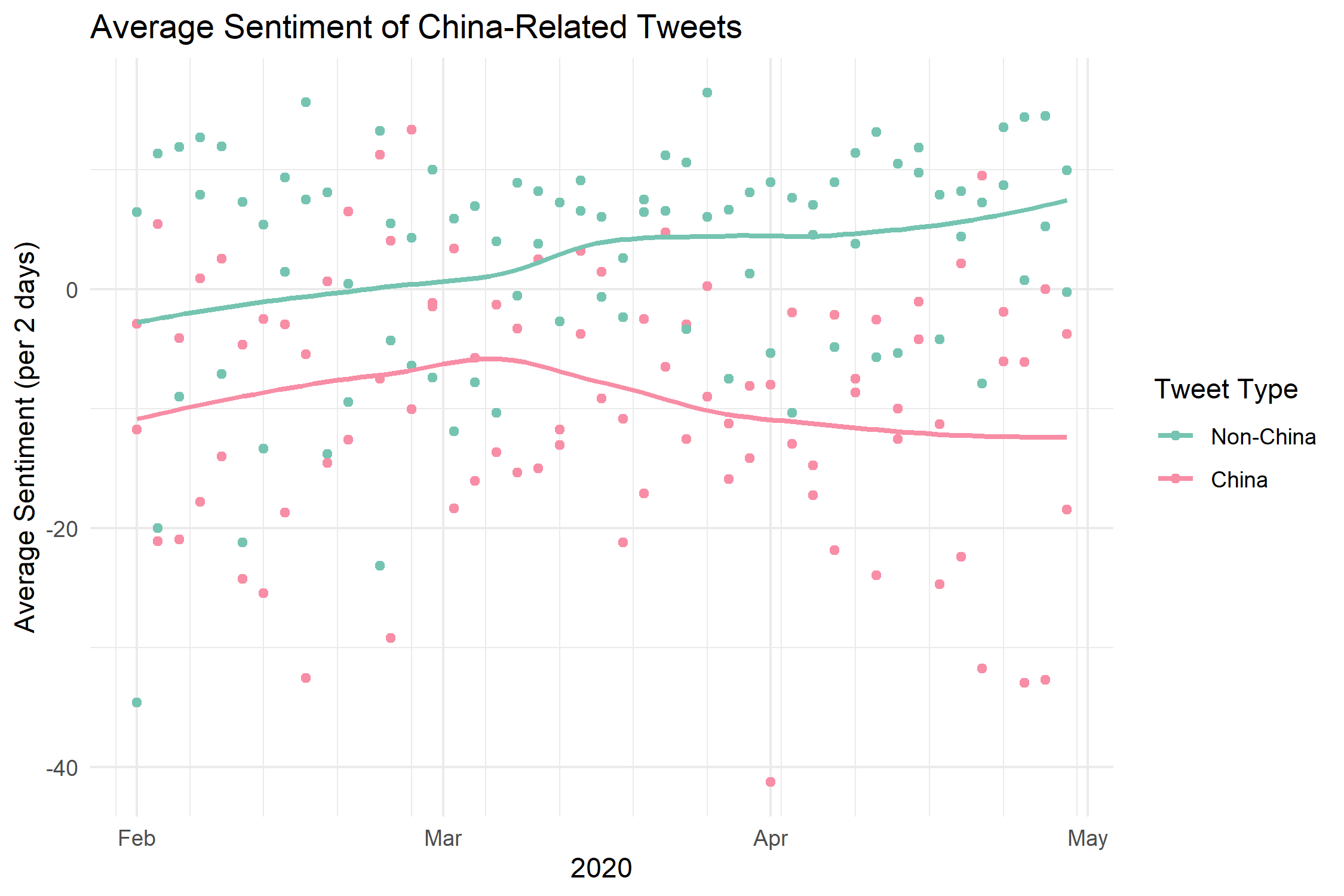
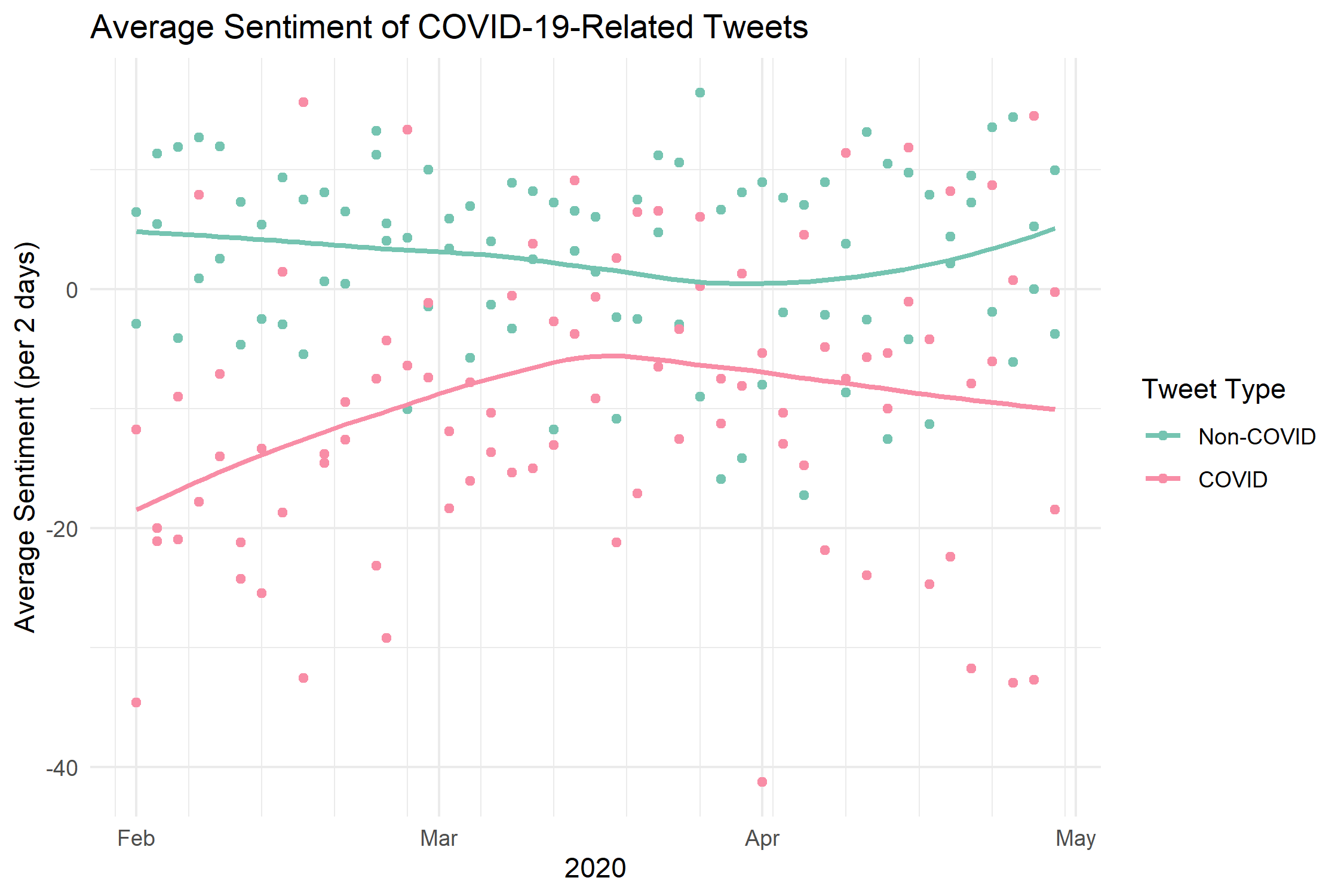
Scatterplots of tweet sentiment distributions using the VADER compound score (-1.0 to 1.0 from negative to positive; scaled by a factor of 100).
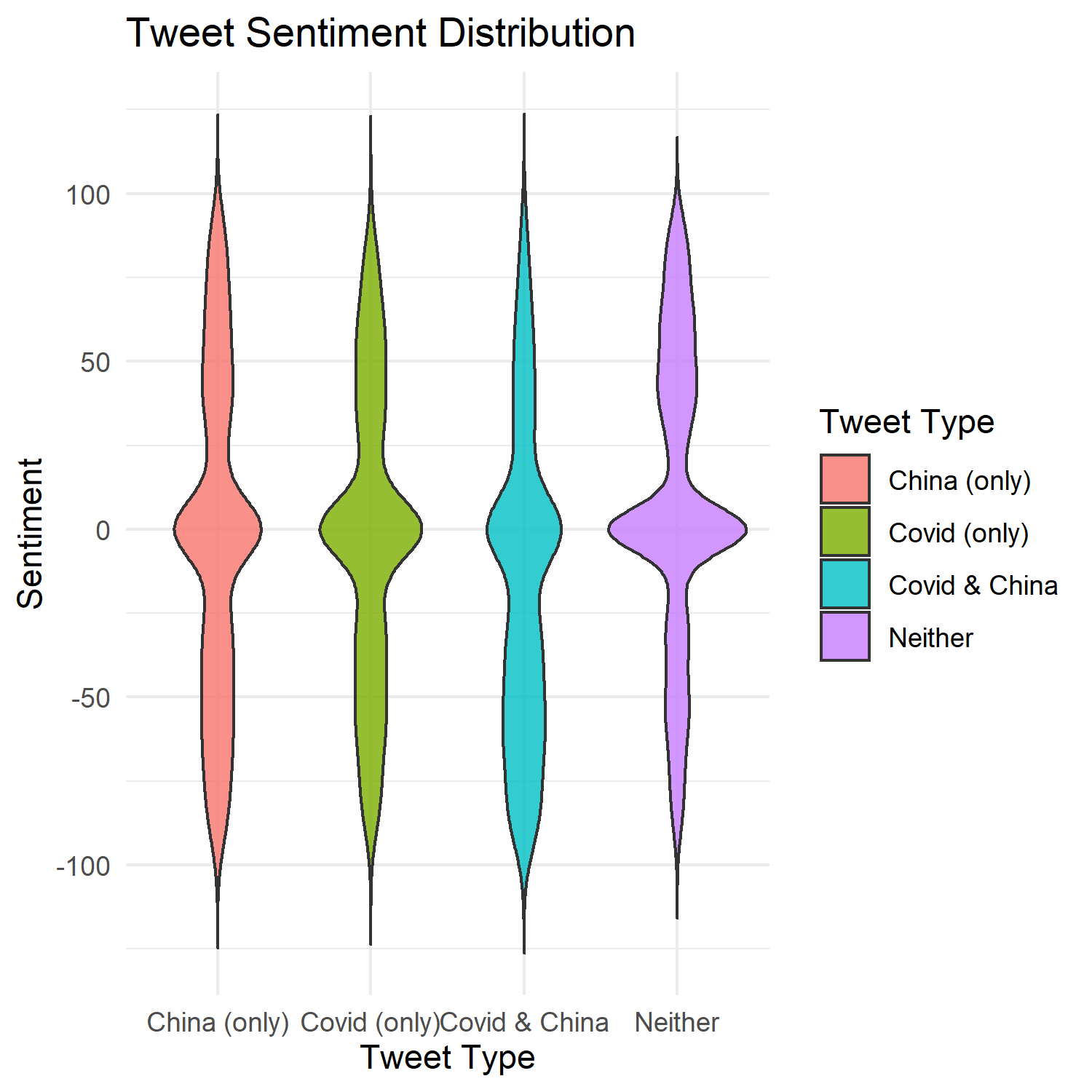
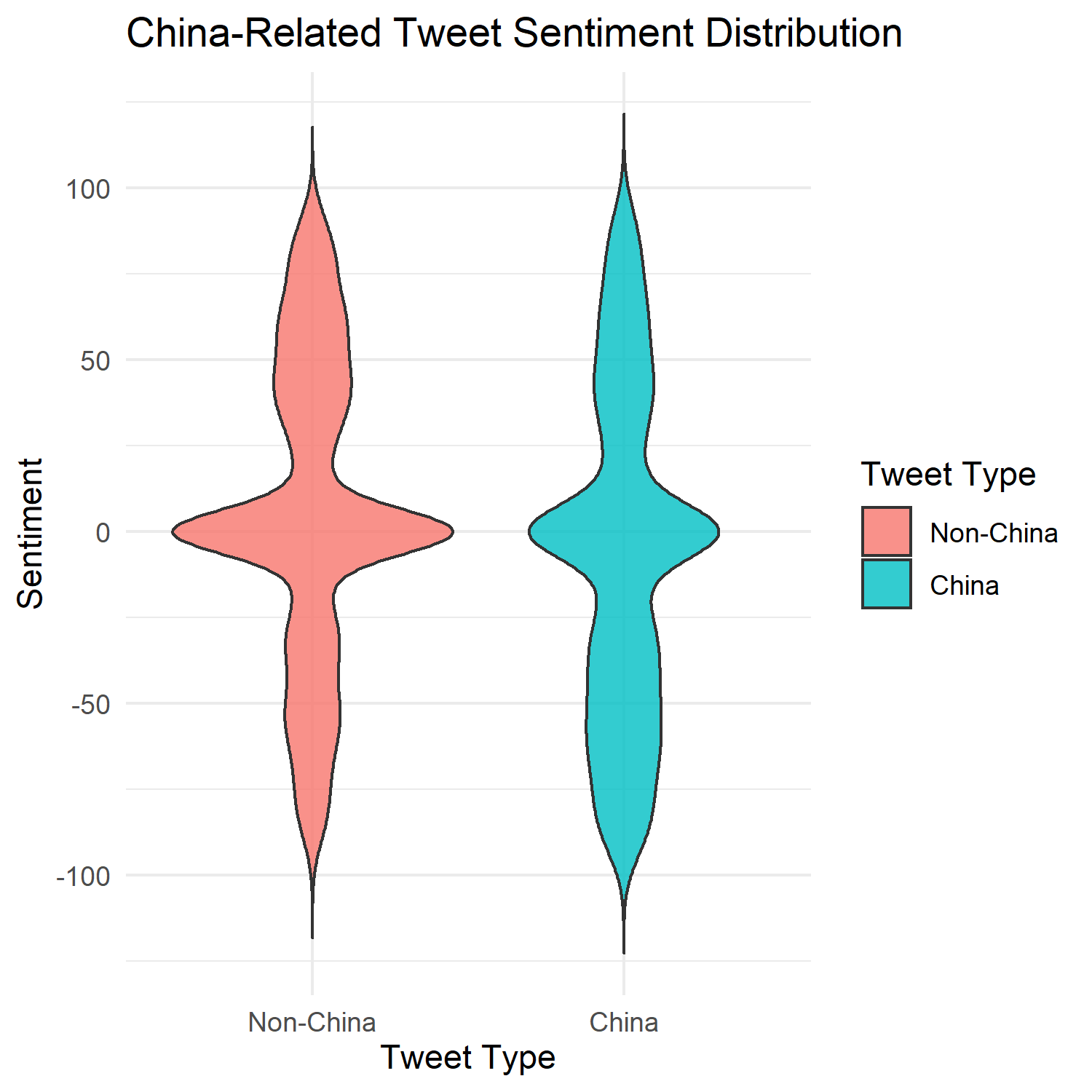
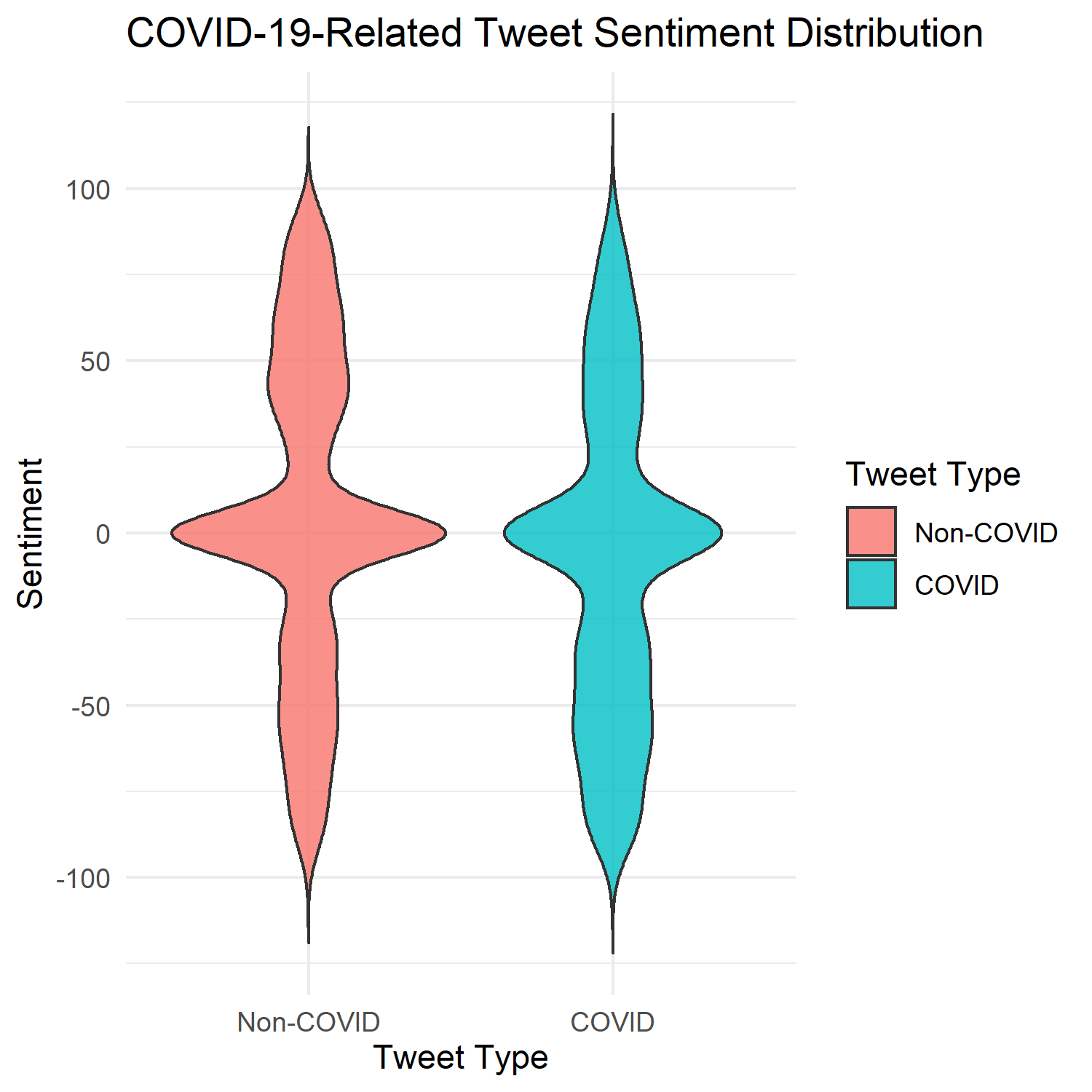
Violin plots of tweet sentiment distributions using the VADER compound score (-1.0 to 1.0 from negative to positive; scaled by a factor of 100). I love violin plots — much cooler than boxplots!
challenges (and overcoming them)
Having never had to really pull and work with my own dataset before, I wasn’t exactly sure where to start. And once I did get momentum, I ran into a few potholes along the way. Here are the main insights I gained while working on this project:
Make a gameplan.
And a detailed one! I made a doc called LING190 Final Project Tracker where I first lay out my research question, the main tools and resources I would use to pull the data, and how I would store my data. A precursor to this was a prior brainstorming doc, which had a bunch of miscellaneous resources and datasets that I was considering using.
Change that gameplan if you need to.
i.e., Be flexible. While my initial gameplan helped orient me and breakdown my project into manageable parts, I had to be open-minded and adjust to unforeseen circumstances, including…
using Tweepy to gather Tweets as a Twitter Developer constrains you to Tweets only from the past week, leading me to find GetOldTweets3
querying for GetOldTweets3 between February 1 to April 30 only really returned February 1 tweets, so I had to alter my code and iterate through each day for a good distribution of tweets
After laboriously gathering ~ 9000 random tweets and processing the data, I realized only about 25 were about coronavirus… and had to change my data collection process:
about 1/2 of the dataset was via querying random, and also China-related tweets using GetOldTweets3
randomly iterating through Tweet ID files of 100,000,000+ tweets on the COVID-19-Tweet-IDs dataset to collect an aggregate Tweet list, re-retrieving their meta-data via Hydrator, then reloading that JSONL into Jupyter Notebook to process as a list of JSON entities
My random-effects mixed model (the test I was using to see if my variables were significant) was failing to converge… so I had to quickly become an R-nerd and rearrange my dataset to merge my covid-word and china-word columns into one and duplicate entries if needed
TLDR; While an initial plan is crucial to establish your initial trajectory, keep a few back-up routes in mind, and don’t be afraid to make some changes to keep plodding along. You can do it!
Stay organized.
In my LING190 Paper Tracker document, after every day of progress, I summarized what I did and listed some action points to complete for next time. And, I made sure to include every resource link I used — yes, even all the ones from StackOverflow and random forums — from figuring out how to read JSON files into Python, to how to draw circle word-clouds with ggplot in RStudio.
Sometimes with coding, after finding a fix online, we just insert it into our code, have it magically work, and forget about what we just used — so for reference in case of future projects, I wanted to document all the nooks and crannies of online resources I delved into. And scrolling back on the 11-page tracker full of URL lists and small steps for project sections, I feel pretty proud of everything I accomplished!
Remember your support system.
For me, my LING190 teaching fellow was SUPER helpful. A month before the project began, I brainstormed with him over Zoom to translate my floating ideas into a quantitative model of predictor vs. response variables to test with my data. With my dataset issues, while I was already considering it, his suggestion gave me the boost of confidence to shake off my discouragement and reconfigure my data collection. And when I ran into my issues of R-testing, my professor helped clarify random effects conceptually, and suggested how I could reconfigure my dataframe. I was grateful to have mentors who could advise me along my first data/CS-related research project, whose suggestions I could take to propel me further along my self-learning journey.
And, it’s not just about your direct academic/career support system. As I was slogging through the last parts of my paper and graph-making in R, my older sister cheered me on, making me tea lattes, taking a brief baking break with me (we made mochi muffins!), and celebrating with me with ice cream after I submitted my assignment. I also couldn’t have made it through without her!
Celebrate!
With ice cream, a nap, a Netflix sesh, what have you! Even if your project won’t win you a Nobel Prize of some sort, you’ve contributed your intellectual curiosity and courage, crafting and putting out into the world something meaningful that did not exist before. We’re advancing in our own unique journeys, and I’m glad that I’ve added this extra stretch of road to the paths I’ve traveled on.